
今天起如月ユナ最新番号,ChatGPT 崇敬插足「4」时期。
就在刚刚,OpenAI 官宣推出 GPT-3.5 Turbo 的替代品——GPT-4o mini,顾名念念义,这是 GPT-4o 更小参数目的简化版块。
即日起,ChatGPT 的免用度户、Plus 用户和 Team 用户齐大约使用 GPT-4o mini。下周,企业版客户也将取得使用 GPT-4o mini 的权限。
OpenAI 官方暗意,「这一变化适宜咱们让所灵验户齐能享受到 AI 期间克己的观点。」

主打低资本和快速反应才能的 GPT-4o mini 适用于多种哄骗场景。
举例,它不错撑握需要不时或同期调用多个模子的哄骗要领(如同期调用多个 API),大约贬责大批高下文信息(如竣工的代码库或对话记载),以及通过快速及时的文本回应与客户进行互动(如客户功绩聊天机器东说念主)。
具体来说,GPT-4o mini 目下在 API 中提供了文本和图像贬责功能,后续还将迟缓增多对视频和音频的撑握。
该模子大约贬责多达 128K token 的长高下文,学问库终局日历为 2023 年 10 月份,况且对非英文本体的撑握更友好。

ChatGPT 截图
从 OpenAI 共享的基准测试服从来看如月ユナ最新番号,GPT-4o mini 在推理基准服从 MMLU 上得分为 82%,而 Gemini Flash 为 77.9%,此前主打极高性价比的 Claude Haiku 为 73.8%。
GPT-4o mini 在数学推理和编程任务方面也通常进展出色,远超市集上的其他袖珍模子。
在 MGSM 数学推理才能基准测试中,GPT-4o mini 得分达到了 87.0%,而 Gemini Flash 的得分为 75.5%,Claude Haiku 的得分为 71.7%。
GPT-4o mini 在 HumanEval 基准测试中通常再次展现上风,得分达到 87.2%,而 Gemini Flash 的得分为 71.5%,Claude Haiku 的得分为 75.9%。
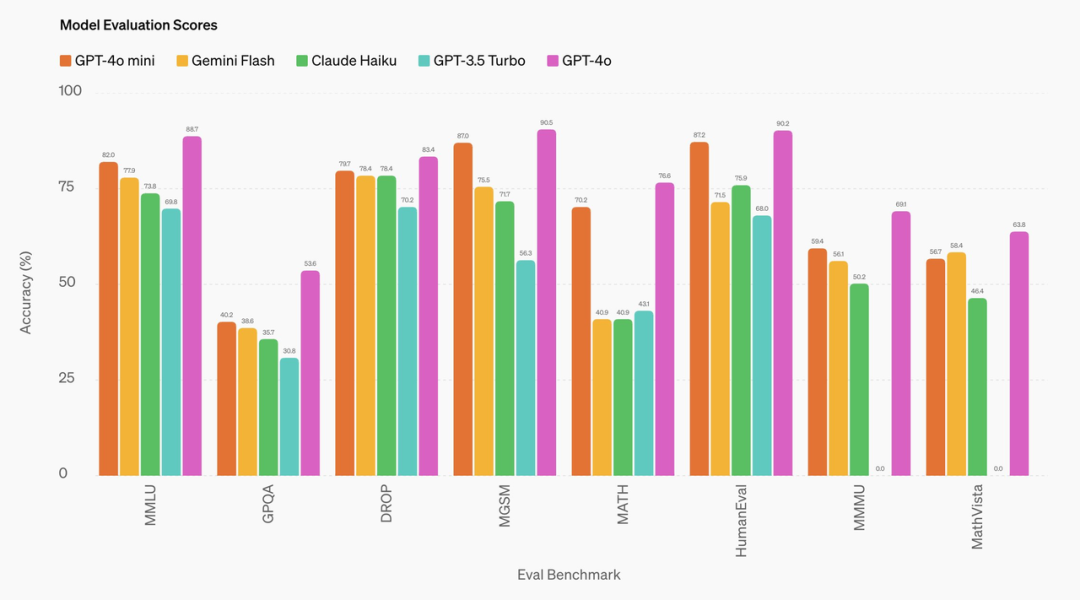
而在多模态推理 MMMU 中,GPT-4o mini 也进展出色,得分为 59.4%,而 Gemini Flash 得分为 56.1%,婷婷五月Claude Haiku 得分为 50.2%。
尤为显眼的是,GPT-3.5 Turbo 在这些基准测试中的得分均不如 GPT-4o mini,致使不错说被全面碾压。此外,GPT-4o mini 在大模子盲测竞技场 LMSYS 中的进展也要优于 GPT-4T 01-25。
除了性能上的增强,GPT-4o mini 也化身价钱屠户,要给 API 市集带来小小的颠簸。@ArtificialAnlys 在 X 上发布了一些模子的价钱对比,足以看出其价位水准:
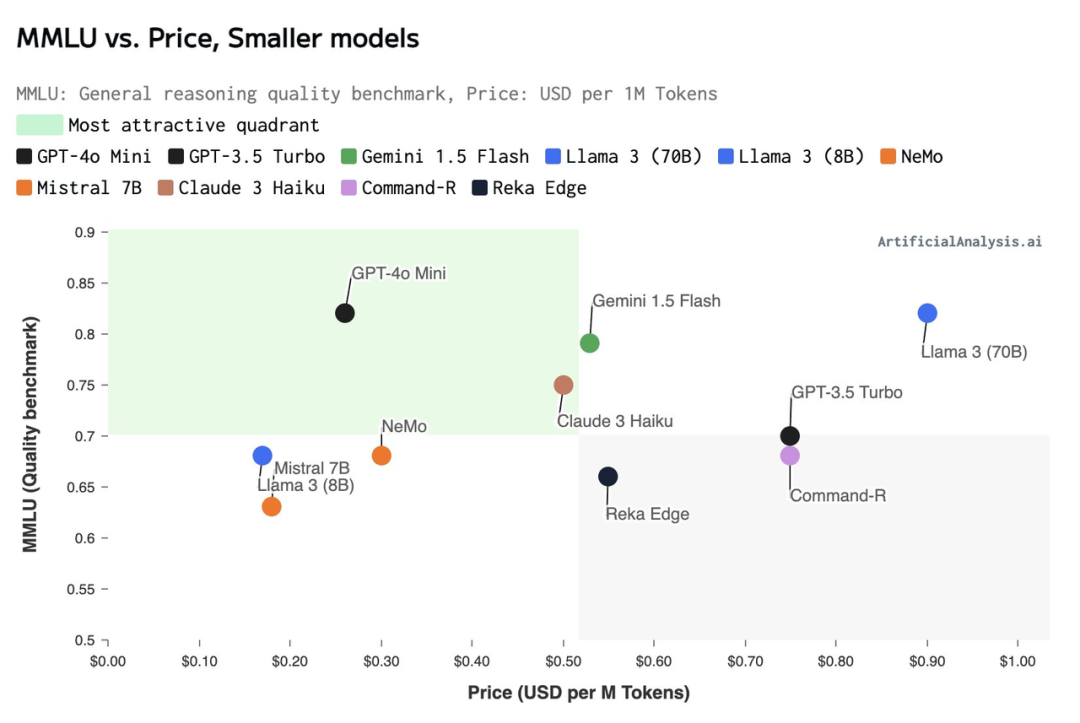
OpenAI 暗意,GPT-4o mini 当今可在 Assistant API、Chat Completions API 和 Batch API 中手脚文本和视觉模子使用。
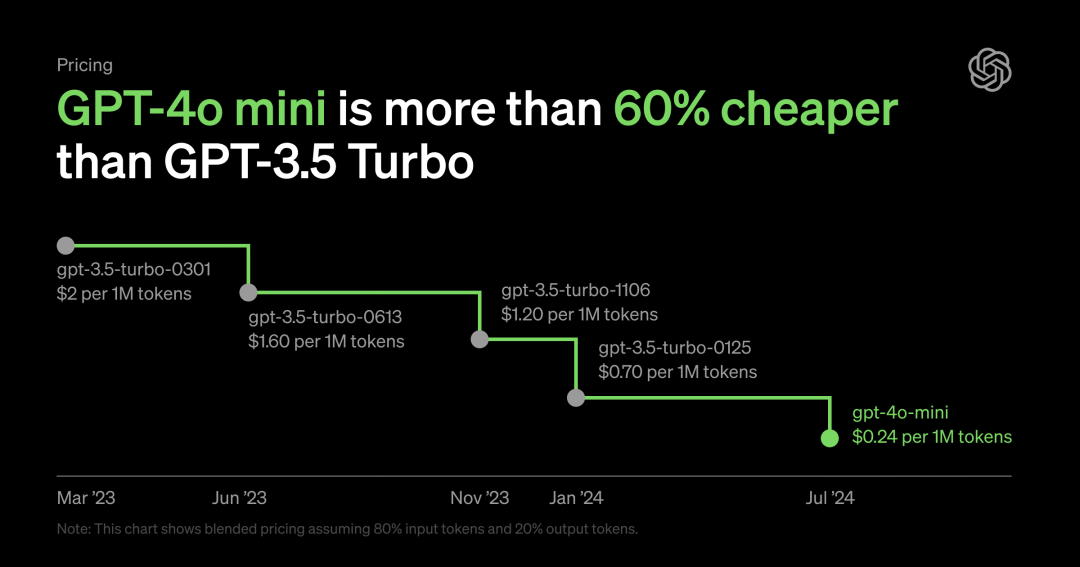
GPT-4o mini 每100 万输入 token 价钱为 15 好意思分,每 100 万输出 token 价钱为 60 好意思分,比 GPT-3.5 Turbo 低廉卓著 60%。
也即是说,GPT-4o mini 生成一册 2500 页的书,价钱只需要 60 好意思分。
对于 GPT-4o mini 的到来,OpenAI CEO Sam Altman 在 X 平台发文感喟:
回归 2022 年,其时宇宙上着手进的模子是 text-davinci-003。与当今的新模子比较,它的性能要差得多。而且,它的使用资本比当今的新模子逾越 100 倍。
另外,接头到模子的安全性问题,OpenAI 还邀请了 70 多位来自社会样子学和诞妄信息盘问等领域的大众对 GPT-4o 的潜在风险进行了测试并凭证反馈服从进行更动。
同期基于这些告戒,OpenAI 还接受一些新的期间来增强对 GPT-4o mini 逃狱袭击等防护才能,使其在大界限哄骗中愈加安全,也愈加自如可靠。
本年以来,国表里掀翻了新一轮大模子价钱战,但没预料的是,OpenAI 也用反应速率更快、资本更低的 GPT-4o mini 模子加入了本就乱成一锅粥的战局。

Altman 更是将其形色为「towards intelligence too cheap to meter」。
手脚 GPT-3.5 Turbo 的免费替代品,GPT-4o mini 在性能方面也没落下,致使也比同量级的 Claude 3 Haiku 和 Gemini 1.5 Flash 还要好。 不少网友在体验事后也齐给出了一致好评。
值得一提的是,对于咱们刻骨铭心的 GPT-4o 语音花样如月ユナ最新番号,Altman 也露馅将在本月晚些时候到来,届时 APPSO 将第一时期跟进。